本章主要介绍几种注意力机制的变体,包括MHA、MQA、GQA等
一、MHA
MHA(Multi-head Attention)是Transformer原论文中首次提出并使用的 Self-Attention 机制,是标准的多头注意力机制,有H个Query、Key 和 Value 矩阵。
MHA 由多个平行的自注意力层组成,每个层都可以关注到输入的不同部分。而每个注意力头都有自己的感知域(parameter sets),可以独立学习输入中的不同特性。然后,将所有头的输出拼接后,通过一个线性变换,得到最终的输出。
MHA的优势在于它能同时捕获输入数据的多个不同特性。事实上,不同的”头”可以分别专注于词序列的不同方面,例如语义、语法等。
详细可见Transformer详解
二、MQA
Multi-Query Attention,在Fast Transformer Decoding: One Write-Head is All You Need提出的,是MHA的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量,以此来达到提升推理速度,但是会带来精度上的损失。
三、GQA
Grouped-Query Attention(分组查询注意力),同样,也是Google在2023年,于GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints提出的一种MHA变体,GQA将查询头分成G组,对于Query是每个头单独保留一份参数,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。
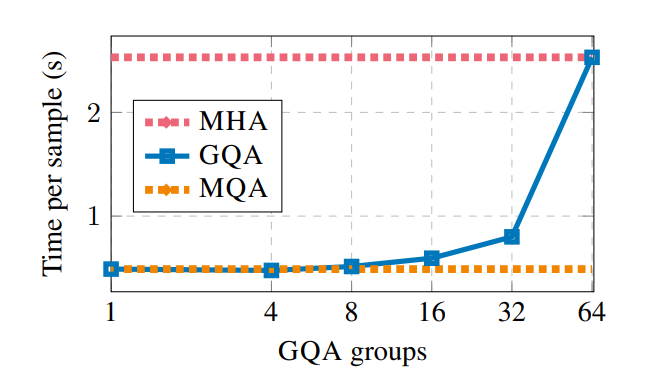
中间组数更多导致插值模型的质量高于 MQA,但比 MHA 更快。从 MHA 到 MQA 将 H 键和值头减少到单个键和值头,减少了键值缓存的大小,因此需要加载的数据量 H 倍
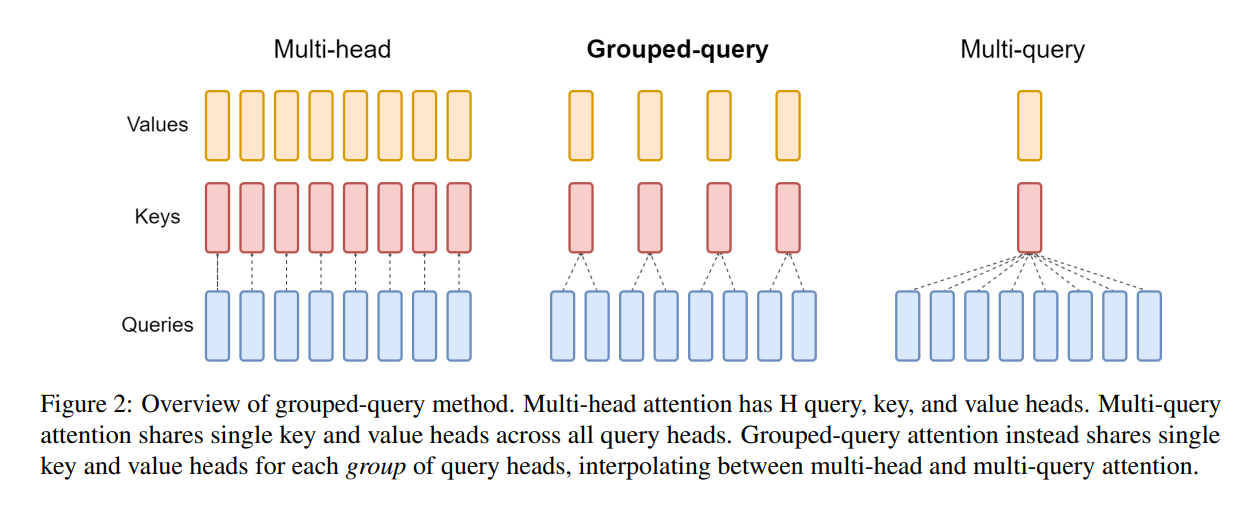
从下图可以发现,当group为1是,GQA是单个组,因此具有单个Key 和 Value,等效于MQA。当group等于H时,GQA等效于MHA。
为什么KV是一组呢?
个人理解
从宏观上确定谁作为query、key和value是很重要的。正确的设计可以帮助模型更有效地捕捉信息。再举一个例子:
假设我们有一个教室里的学生和老师的场景。学生需要请教老师问题,而老师拥有知识和答案。在这种情况下,学生可以被视为query,因为他们提出问题并寻求答案。老师则可以被视为key和value,因为他们拥有可以解答问题的知识(key)和实际答案(value)。
也可以从维度的角度出发,KV的维度是一致的,Q的维度可能根据长度有所变化