本章主要介绍几种分类任务常见的指标,包括Accuracy、Precision、Recall、F1-score等
一、前言
对于分类任务常见的评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、ROC 曲线(Receiver Operating Characteristic Curve)等。
混淆矩阵
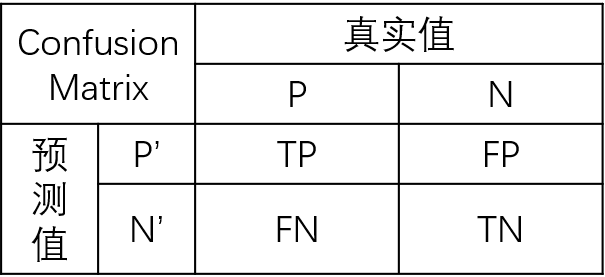
如上图所示,要了解各个评价指标,首先需要知道混淆矩阵,混淆矩阵中的 P 表示 Positive,即正例或者阳性,N 表示 Negative,即负例或者阴性。你也可以把 P 和 N 分别理解为二分类中的 1-0
- TP:实际为正,预测为正的样本数量
- FP:实际为负,预测为正的样本数量
- FN:实际为正,预测为负的样本数量
- TN:实际为负,预测为负的样本数量
另外
- TP+FP:表示所有预测为正的样本数量
- TN+FN:表示所有预测为负的样本数量
- TP+FN:表示实际为正的样本数量
- TN+FP:表示实际为负的样本数量
二、准确率
准确率是分类正确的样本占总样本个数,即:
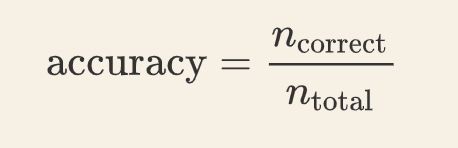
准确率是分类问题中最简单最直观的评价指标,但存在明显的缺陷。比如正负样本的比例不均衡,假设样本中正样本占 90%,负样本占 10%,那分类器只需要一直预测为正,就可以得到 90% 的准确率,但其实际性能是非常低下的。
三、精确率
精确率指模型预测为正的样本中实际也为正的样本 占 被预测为正的样本的比例。计算公式:
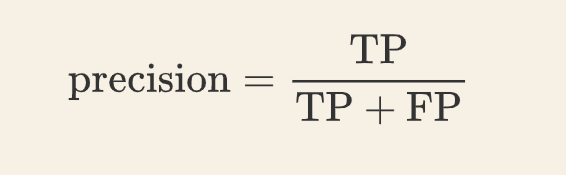
| 实际 | 0 | 1 | 2 | 0 | 1 | 2 |
|---|---|---|---|---|---|---|
| 预测 | 0 | 2 | 1 | 0 | 0 | 1 |
对于以上预测-实际的结果,Precision还可以细分为:Macro-Precision 和 Micro-Precision
Macro-Precision(宏观上的角度):
求出每一类个类别的Precision,再求出加和平均
对于一个N分类的任务来说,其所有的预测情况是一个N×N的二维表格,每一类的Precision,就是对角线对应的位置的样本数 除以 当前类别的行上的所有样本总数
Micro-Precision(微观上的角度):
对于每一个类,分别计算出TP,FP,最后统计所有类别的TP加和, FP加和,再用Precision的公式计算Micro-Precision
| 类别 | TP | FP | FN |
|---|---|---|---|
| 0 | 2 | 1 | 0 |
| 1 | 0 | 2 | 2 |
| 2 | 0 | 1 | 1 |
四、召回率
召回率指实际为正的样本中,预测也为正的样本 占 实际为正的样本的比例。计算公式为:
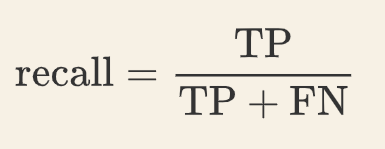
Macro-Recall(宏观上的角度):
求出每一类个类别的Recall,再求出加和平均
对于一个N分类的任务来说,其所有的预测情况是一个N×N的二维表格,每一类的Recall,就是对角线对应的位置的样本数 除以 当前类别的列上的所有样本总数
Micro-Recall(微观上的角度):
对于每一个类,分别计算出TP,FN,最后统计所有类别的TP加和, FN加和,再用Recall的公式计算Micro-Recall
五、F1-Score
F1-score 是精确率和召回率的加权平均值,计算公式为:
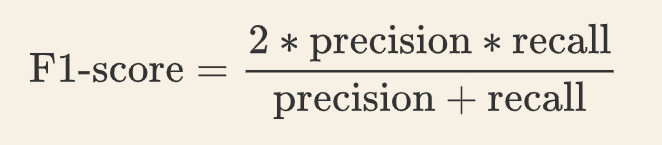
Macro-F1(宏观上的角度)
Micro-F1(微观上的角度)
在原本的公式上用各自在相应的Macro-Micro Pre和Recall上计算即可
Precision 体现了模型对负样本的区分能力,Precision 越高,模型对负样本的区分能力越强
Recall 体现了模型对正样本的识别能力,Recall 越高,模型对正样本的识别能力越强
F1-score 是两者的综合,F1-score 越高,说明模型越稳健
第1种情况:各个类别下样本数量不一样多但相差不大
在这情况下,用macro-f1与micro-f1都行。但是当数据中存在某类f1值较大,有的类f1很小,在这种情况下,macro-f1这时候就明显会受到某类f1小的值影响,会偏小。
第2种情况:当各类别下数据量不一样多但相差很大
这种情况下,也就是数据极度不均衡的情况下,micro-f1影响就很大,micro-f1此时几乎只能反映那个类样本量大的情况,micro-f1≈A类f1。
第3种情况:当各类别下数据量一样多
这种情况下,选用macro-f1与micro-f1都差不多,其中macro-f1与weight-f1值是一样的。但这里macro-f1也会出现受到某类f1小的值影响,偏小。
- ROC曲线:ROC曲线(Receiver Operating Characteristic Curve)是一种描绘分类器性能的图形工具,它显示了在不同阈值下分类器的真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)之间的关系。
真阳性率的其实是召回率(越高越好),假阳性率(检测为负的样本中,多少样本是正的,越接近0越好),公式是: FP / FP + TN
- AUC值:AUC(Area Under the Curve)值表示ROC曲线下的面积,用于衡量分类器性能。AUC值越接近1,表示分类器性能越好;反之,AUC值越接近0,表示分类器性能越差。