本章主要介绍不同的浮点数类型,以及混合精度训练的方法
一、前言
如今大模型的训练、推理、部署,涉及各种各样的精度
浮点数精度:双精度(FP64)、单精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4位精度(FP4、NF4)
量化精度:INT8、INT4 (也有INT3/INT5/INT6的)
不同的浮点数存储方式:
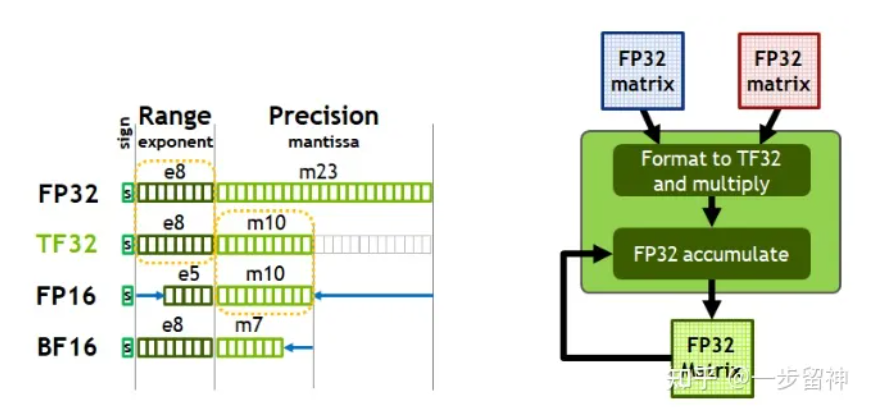
在计算机中,浮点数存储方式,由由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。符号位都是1位,指数位影响浮点数范围,小数位影响精度。
还会经常碰到BF16
Brain Float 16,由Google Brain提出,也是为了机器学习而设计。由1个符号位,8位指数位(和FP32一致)和7位小数位(低于FP16)组成。所以精度低于FP16,但是表示范围和FP32一致,和FP32之间很容易转换
float16和float32相比起来,总结下来就是两个原因:内存占用更少,计算更快。
内存占用更少:这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
- 模型占用的内存更小,训练的时候可以用更大的batchsize。
- 模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。
计算更快:
- 目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍
二、混合精度训练
模型训练中的显存占用主要包括以下几个方面:
- Model State Memory
- 模型本身的参数
- 参数的梯度
- 优化器状态:例如Adam优化器的话,对于每个参数还需要保存动量和方差
由于FP16的计算效率比FP32要高得多, 所以大模型往往是使用混合精度训练的
1、模型参数W是FP32, Momentum和Variance也是FP32, 统称为Model States
2、前向传播时,将FP32的Parameter新建一份FP16备份。然后用FP16正常做Forward和Backward
3、Loss计算:该场景中loss计算复杂,涉及到许多exp, log等可能会发生FP16溢出的不稳定操作,因此loss计算在FP32精度下进行
4、反向计算过程中,首先乘以Loss Scale值,避免反向梯度过小而产生下溢
5、FP16参数参与梯度计算,其结果将被转换回FP32
6、除以loss scale值,还原被放大的梯度
7、判断梯度是否存在溢出,如果溢出则跳过更新,否则优化器以FP32对原始参数进行更新
最终输出的模型权重应该是FP32而不是FP16
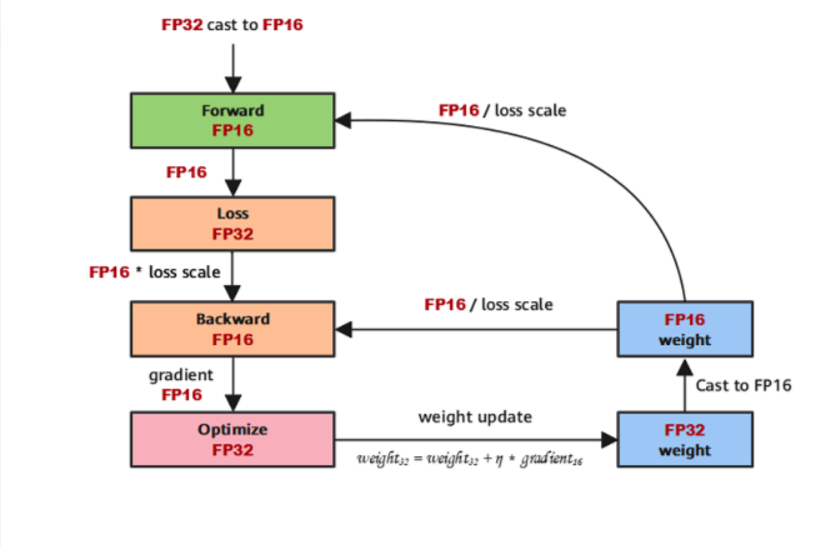
具体而言,混合精度训练使用了三个技术。
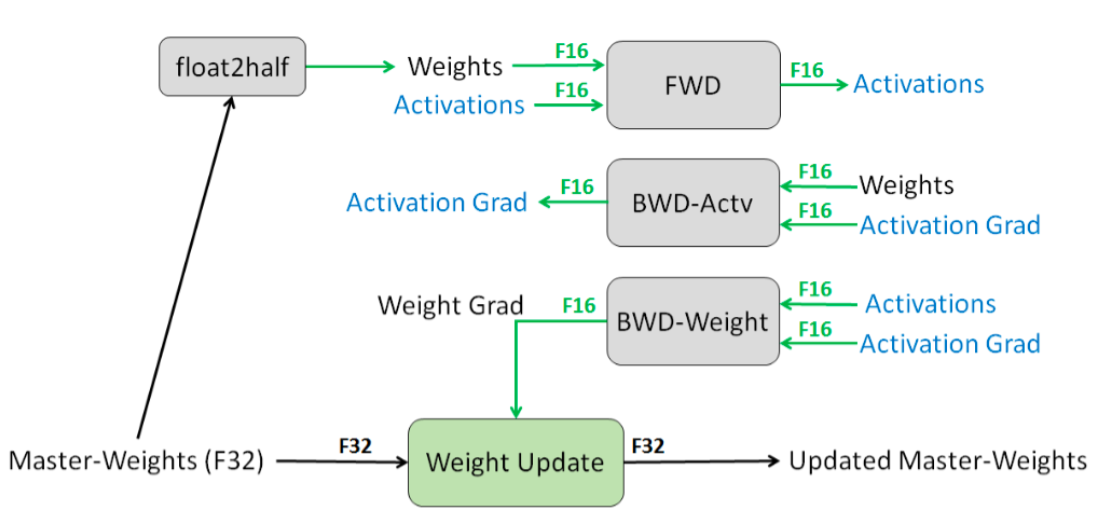
FP32模型权重
FP32 master copy of weights。模型的权重使用FP32来表示,保证了数值准确性。在前向和反向计算时,先将FP32权重转化成FP16,同时还保留一份FP32的Master Copy。最后将梯度更新到Master Copy上。那么计算时可以获得FP16的速度提升,而权重这样重要的数据仍然以FP32的高精度来保存。
Loss Scale
FP16的精度范围有限,训练一些模型的时候,梯度数值在FP16精度下都被表示为0,如下图所示:
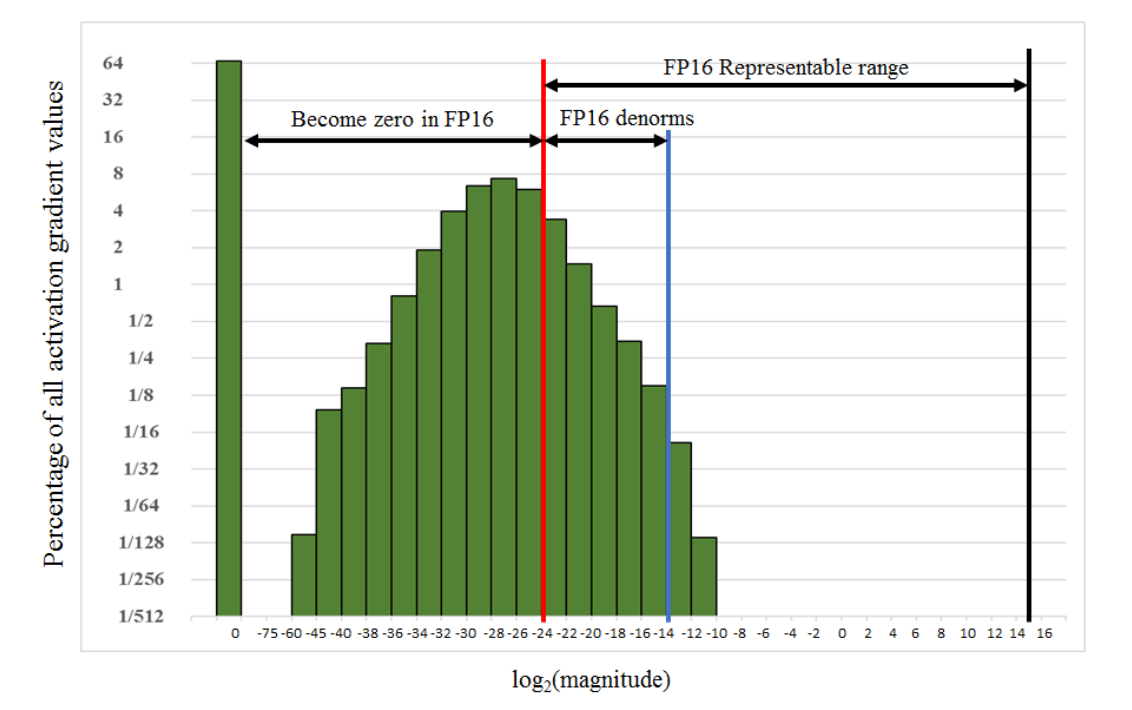
为了让这些梯度能够被FP16表示,可以在计算Loss的时候,将loss乘以一个扩大的系数loss scale,比如1024。这样,一个接近0的极小的数字经过乘法,就能过被FP16表示。这个过程发生在前向传播的最后一步,反向传播之前。
loss scale有两种设置策略:
- loss scale固定值,比如在[8, 32000]之间;
- 动态调整,先将loss scale初始化为65536,如果出现上溢或下溢,在loss scale值基础上适当增加或减少。