使用LoRA微调LLaMa2,训练LLM在给定上下文无法回答用户问题时拒绝回答的能力,而不是胡说。
1、实验简介
选题:《基于 https://github.com/hiyouga/LLaMA-Factory 开源项目跑通一个Chat机器人》
选择的是方向1:尝试对模型进行简单的指令微调,数据集可以是自己构造的、可以是开源的;
Github代码仓库:https://github.com/LimOkii/nlp_lab
1.1 任务简介
本次大作业我想微调出一个LLM,使之能够判断给定的语料是否能解答用户问题,不能编造答案。如果根据所有的内容都无法得出明确的结论,需要回复“对不起,根据参考资料无法回答“这些类似的回答。
本次微调的基座采用Meta发布的LLaMa-2-hf-7b-chat版本,训练LLM在给定上下文无法回答用户问题时拒绝回答的能力,而不是胡说。
微调代码参考:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
1.2 数据集介绍
- 本次微调采用的数据集是百度发布的
WebQA
1 | 链接: https://pan.baidu.com/s/1pLXEYtd 密码: 6fbf |
me_train.jsons数据样例如下:
1 | "Q_TRN_005637": { |
这个数据集非常适合做给定上下文的回答问题,evidence即是输入给模型的上下文,question则是用户提出的问题,模型需要根据给定的evidence以及question回答no_answer或者是答案。
2、基座模型LLaMa介绍
本次微调的基座模型采用Meta发布的LLaMa-2-hf-7b-chat版本
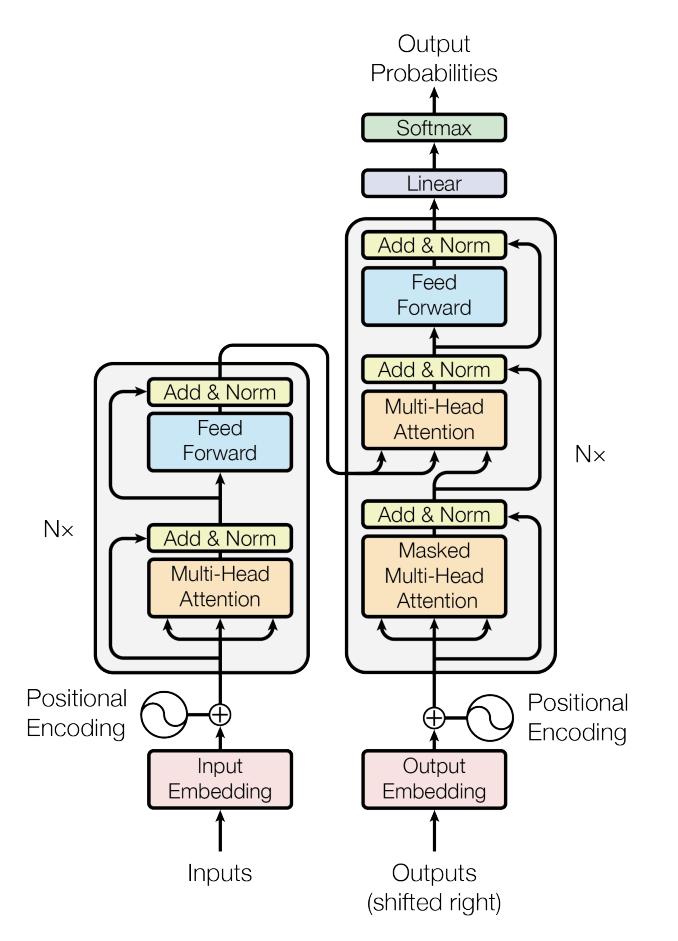
LLaMa2 和 LLaMa 的模型结构基本一致,共用了 32 个 decoder 层。其中每个 decoder 层如上图右半部分所示,LLaMa2 主要是将 Transformer 中的 Layer Norm 换成了 RMS Norm,Multi-Head Attention 换成了 GQA(``LLaMa是MQA), Positional Encoding 换成了 Rotary Encoding(RoPE 旋转位置编码),在前馈神经网络(FFN) 使用 SwiGLU激活函数替换了Transformer中的ReLU` 激活函数。
3、实验步骤
3.1 数据预处理
本次微调代码参考的Chinese-LLaMA-Alpaca-2,指令微调数据格式为Stanford Alpaca:
1 | [ |
需要对WebQA数据集做转换,因此编写了脚本 convert_data_to_llama_train.py
instruction:”请根据给定下文:” + “evidence” + ‘\n’ + “告诉我” + “question” + ‘\n’
input: “”
output:”answer”
- 为了让模型无法回答的输出多样化,如果答案为
no_answer,则从以下模板中随机选择一句回答
1 | # 无法回答时,模型给出的回答样例 |
- 最终转换后的训练数据样例如下:
1 | [ |
3.2 微调训练
3.2.1 LoRA介绍
由于大语言模型参数量十分庞大,当将其应用到下游任务时,微调全部参数需要相当高的算力。为了节省成本,研究人员提出了多种参数高效(Parameter Efficient)的微调方法,旨在仅训练少量参数使模型适应到下游任务。本项目使用LoRA(Low-Rank Adaptation of Large Language Models)进行模型微调。LoRA 方法 可以在缩减训练参数量和 GPU 显存占用的同时,使训练后的模型具有与全量微调相当的性能。
研究表明,语言模型针对特定任务微调之后,权重矩阵通常具有很低的本征秩 (Intrinsic Rank)。研究人员认为参数更新量即便投影到较小的子空间中,也不会影响学习的有效性。因此,提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。具体来说,假设预训练权重为${w_0\ \epsilon \ \mathbb{R}^{dk}}$,可训练参数为${\varDelta W\ =\ BA}$,其中${B\ \epsilon \ \mathbb{R}^{dr} }$,${A\ \epsilon \ \mathbb{R}^{r*d}}$,初始化时,矩阵 ${A}$ 通过高斯函数初始化,矩阵${B}$ 为零初始化,使得训练开始之前旁路对原模型不造成影响,即参数改变量为 0。对于该权重的输入 ${x}$ 来说,输出为式${h\ =\ W_0x+∆W\ x\ =W_0x+BAx}$,LoRA算法结构方法如图:
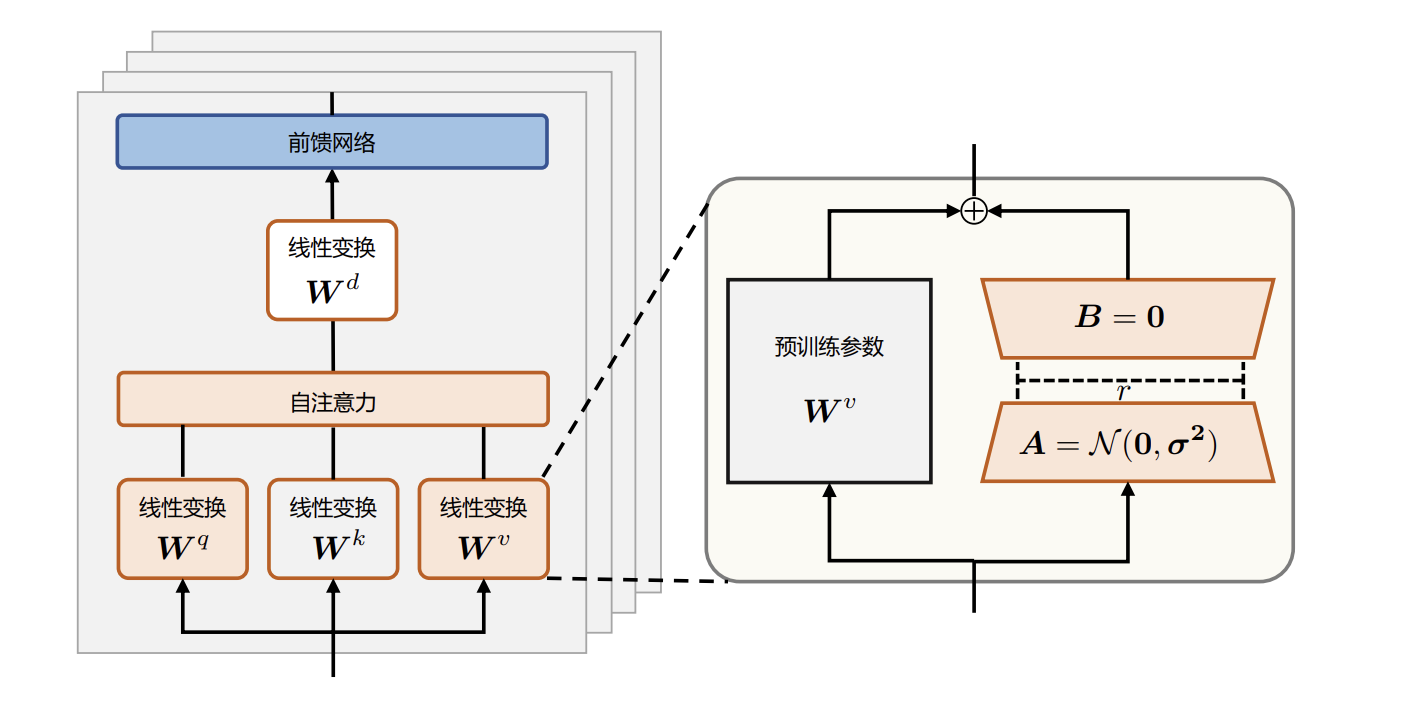
除 LoRA 之外,也其他高效微调方法,如微调适配器(Adapter)或前缀微调(Prefix Tuning)。 适配器方法分别对 Transformer 层中的自注意力模块与多层感知(MLP)模块,在其与其之后的残差连接之间添加适配器层(Adapter layer)作为可训练参数,该方法及其变体会增加网络的深度,从而在模型推理时带来额外的时间开销。当没有使用模型或数据并行时,这种开销会较为明显。而对于使用 LoRA 的模型来说,由于可以将原权重与训练后权重合并,即 ${W\ =\ W_0\ +\ BA}$, 因此在推理时不存在额外的开销。前缀微调是指在输入序列前缀添加连续可微的软提示作为可训练参数。由于模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。这使得前缀微调的模型性能并非随着可训练参数量单调上升。 在文献的实验中,使用 LoRA 方法训练的 GPT-2、GPT-3模型在相近数量的可训练参数下, 性能均优于或相当于使用上述两种微调方法。
3.2.2 LoRA微调
数据共40w+条,其中训练数据313910条,其余是验证数据,在单卡A6000 48G显存显卡上采用LoRA方式微调。
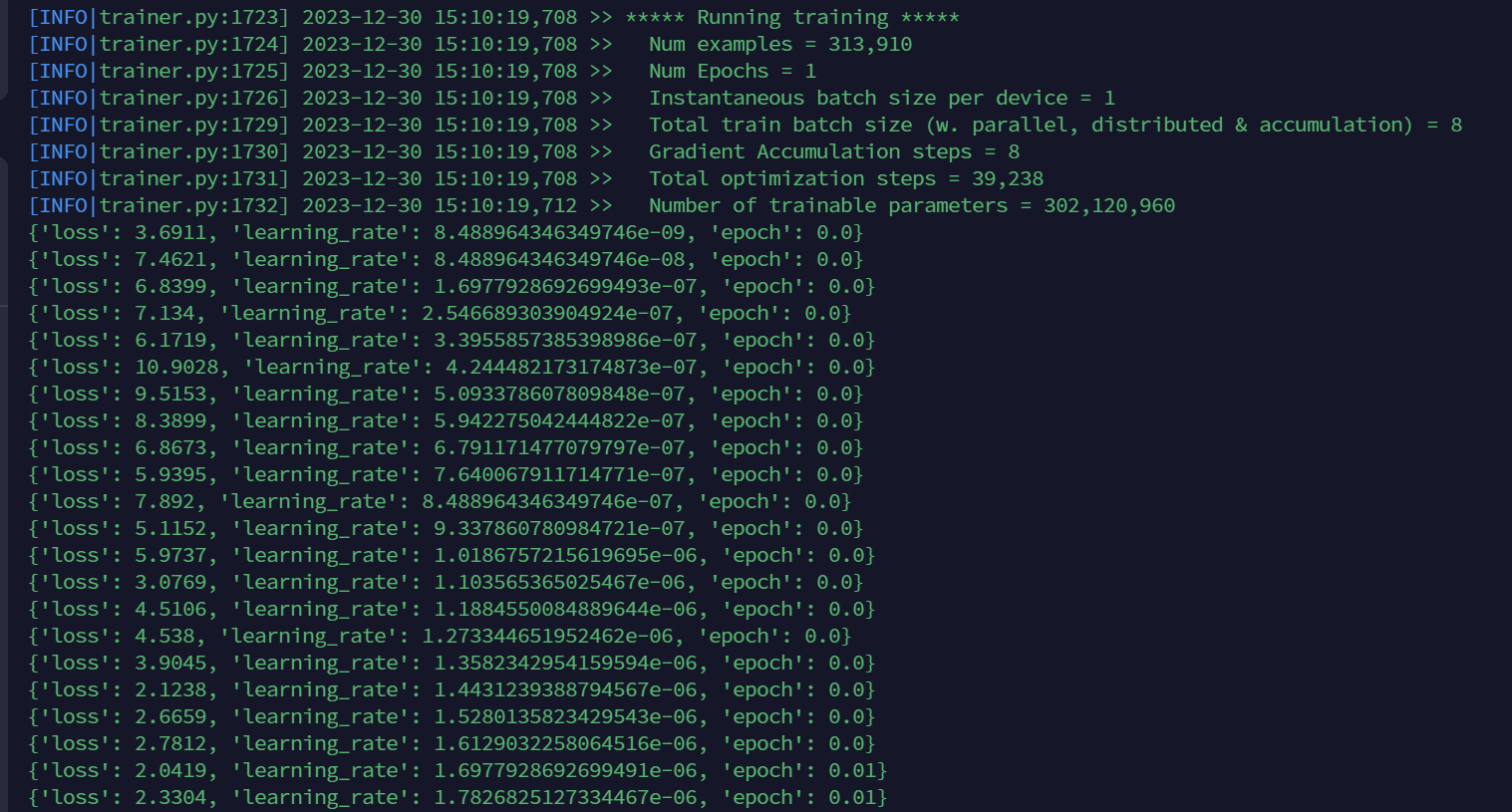
可以看到原版LLaMa2是7b的权重,使用LoRA方式微调,训练参数仅为0.3b,为初始权重的4%左右,大大减少了需要训练的参数量。
在单卡A6000 48G显存训练一个epoch,约57个小时(包括训练时间和评估时间),最终的loss从一开始的7左右降到了0.1上下。
3.2.3 权重合并
手动将LoRA与原版Llama-2合并得到完整模型的流程
确保机器有足够的内存加载完整模型(例如7B模型需要13-15G)以进行合并模型操作
Step 1: 获取原版Llama-2-hf模型
HF格式模型相关文件(可以不用下载safetensors格式模型权重):
1 | config.json |
Step 2: 合并LoRA权重,生成全量模型权重
这一步骤会合并LoRA权重,生成全量模型权重。此处可以选择输出PyTorch版本权重(.pth文件)或者输出HuggingFace版本权重(.bin文件)。执行以下命令:
1 | $ python scripts/merge_llama2_with_chinese_lora_low_mem.py \ |
参数说明:
--base_model:存放HF格式的Llama-2模型权重和配置文件的目录--lora_model:中文LLaMA-2/Alpaca-2 LoRA解压后文件所在目录,也可使用🤗Model Hub模型调用名称(会自动下载)--output_type:指定输出格式,可为pth或huggingface。若不指定,默认为huggingface--output_dir:指定保存全量模型权重的目录,默认为./- (可选)
--verbose:显示合并过程中的详细信息
4、实验结果展示
1 | model = "/data0/luyifei/cant_ans_merge_weight/" |
加载合并后的权重,3个测试样例如下:
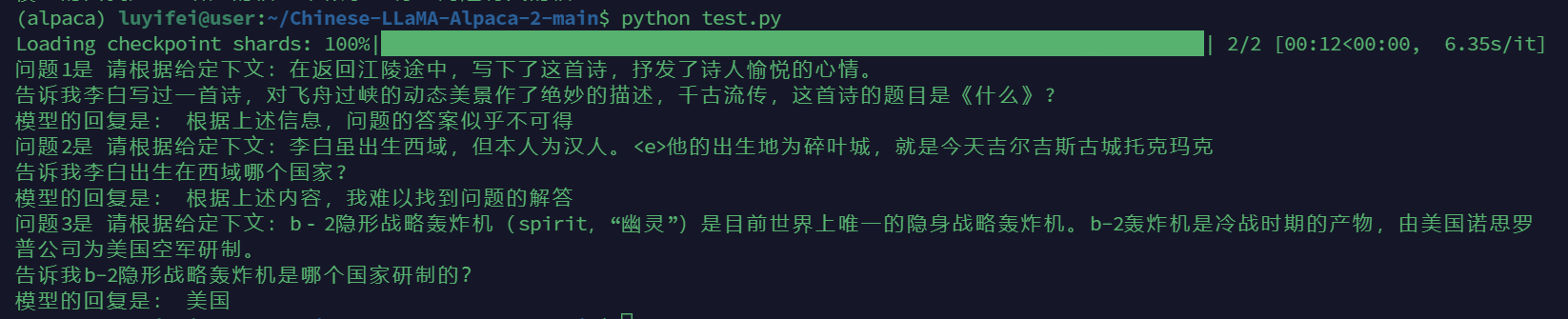
例子1和例子3回答正确
例子2回答错误
例子1中,给定的上下文中没有关于这首诗的题目,因此模型无法回答该问题。
例子2中,给定的上下文中给出了李白的出生地为碎叶城,但是模型却回复无法回答该问题。
例子3中,给定的上下文中告知b-2轰炸机是美国空军研制,模型也能正确回复答案美国
5、总结
使用LoRA方式微调LLaMa,能使大模型一定程度上根据给定的上下文来回答问题。在给定上下文不包含问题的答案时能输出”对不起,我无法回答该问题”等回复,若给定上下文包含问题的答案,模型也能输出正确答案。
但是当我尝试更多样例测试时,发现模型更容易偏向输出无法回答的回复,即使给定上下文中有明确的问题答案。我总结的分析原因如下:
微调大型模型时,模型可能会倾向于输出一种相对保守的策略,即更倾向于回答无法回答的响应。这可能是因为微调过程中的数据集中,有更多的例子涉及到模型无法从给定上下文中得知答案的情况,导致模型更容易学习到这种“保守”的回答。
有几个可能的原因导致这种现象:
- 数据分布不均衡: 可能时微调数据中无法回答的例子相对较多,模型可能会更容易学习到输出类似于“无法回答”的响应。
- Loss 函数设计: 微调过程中使用的损失函数可能也影响了模型的学习方向。如果损失函数更倾向于对无法回答的情况进行惩罚,模型可能更倾向于产生这样的输出。
- 训练数据中的噪声: 如果微调数据中包含了噪声或错误的标签,模型可能会过度拟合这些错误的标签,导致更多的“无法回答”响应。
下一步尝试的改进方向:
1、检查数据质量: 仔细检查微调数据集,确保标签和上下文对应正确,避免包含噪声或错误的信息。
2、平衡数据集: 确保微调的数据集中有足够的例子涉及到模型可以回答的情况,以及无法回答的情况,以避免数据分布不均衡。