本章是ChatGLM模型概述,涵盖ChatGLM-1、ChatGLM-2
一、前言
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
为了方便下游开发者针对自己的应用场景定制模型,GLM同时实现了基于 P-Tuning v2 的高效参数微调方法,INT4 量化级别下最低只需 7GB 显存即可启动微调。
二、预训练任务
一般预训练模型架构分为三种:自回归(GPT系列)、自编码(Bert系列)、编码器-解码器(T5)
作者概述了它们目前存在的问题:
1、GPT:单向的注意力机制,不能完全捕捉NLU任务中上下文词之间的依赖关系。
2、Bert:编码器可以更好的提取上下文信息,但是不能直接用于文本生成。
之前也有人做过统一这两个架构的工作,但是自编码与自回归本质的不同,不能很好的继承两个架构的优点,于是提出了一个基于自回归空白填充的语言模型(GLM),GLM通过2D的 positional encoding和允许一个任意的predict spans 来改进空白填充预训练。同时,GLM可以通过改变空白的数量和长度对不同类型的任务进行预训练。
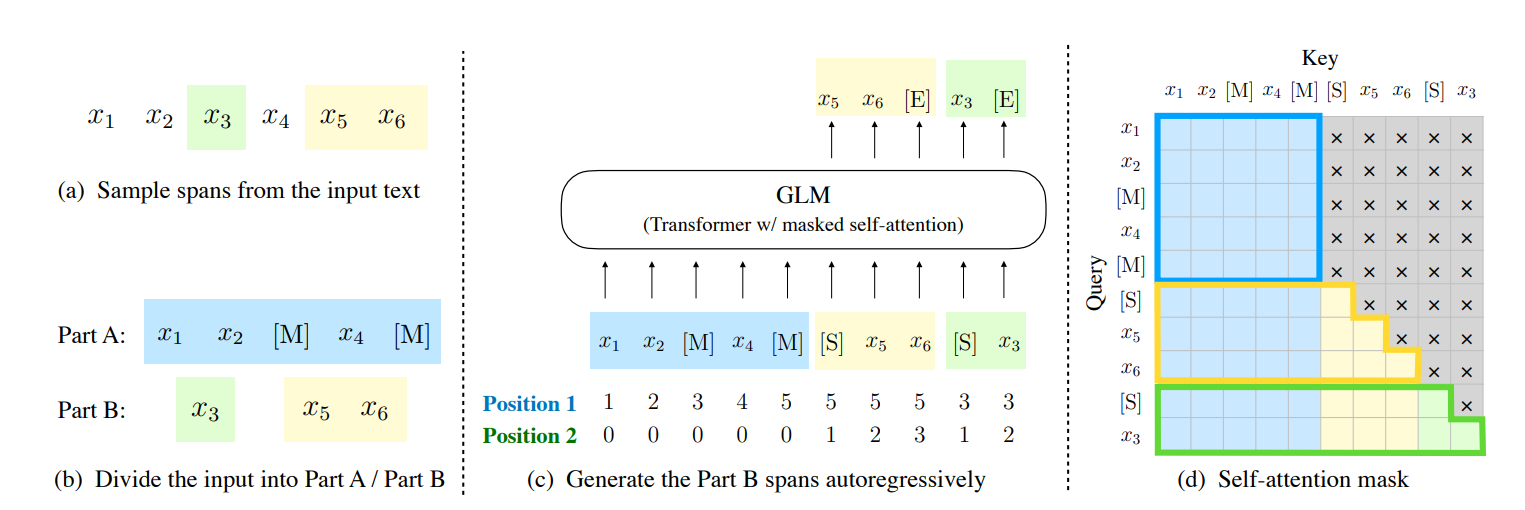
1、给定Input=[x1,x2,x3,x3,x5,x6],然后采样m个 spans。
2、把被采样的部分mask掉,得到Part A。
3、random 被采样的 spans,得到 PartB。
4、把PartA与PartB拼接成一个sequence,Part A部分采用双向注意力,PartB部分采样自回归预测。为了能够自回归生成,padded [start]和[end]
训练文本构建

三、模型结构
GLM在原始single Transformer的基础上进行了一些修改:
1、重组了LN和残差连接的顺序;
2、使用单个线性层对输出token进行预测;
3、激活函数从ReLU换成了GeLUS。
但这部分的修改比较简单常见。核心和亮点还是空格填充任务的设计
四、微调
对于下游NLU任务来说,通常会将预训练模型产出的序列或tokens表达作为输入,使用线性分类器预测label。所以预训练与微调之间存在天然不一致。
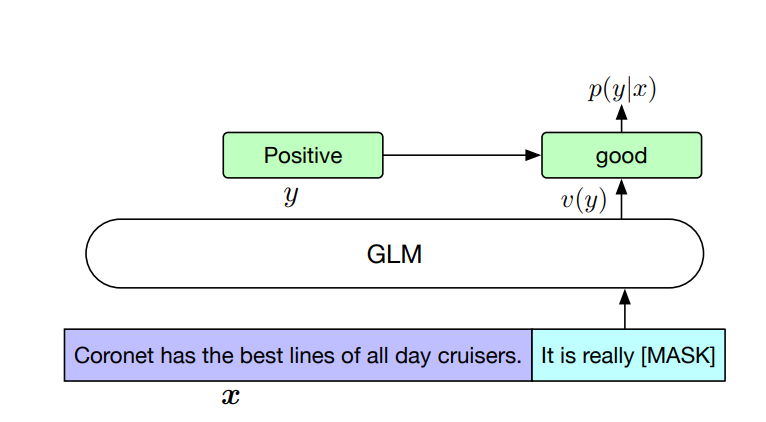
作者按照PET的方式,将下游NLU任务重新表述为空白填充的生成任务。具体来说,比如给定一个已标注样本(x, y),将输入的文本x转换成一个包含mask token的完形填空问题。比如,情感分类任务可以表述为:”{SENTENCE}. It’s really [MASK]”。输出label y也同样会被映射到完形填空的答案中。“positive” 和 “negative” 对应的标签就是”good” 和 “bad”。
其实,预训练时,对较长的文本片段进行mask,以确保GLM的文本生成能力。但是在微调的时候,相当于将NLU任务也转换成了生成任务,这样其实是为了适应预训练的目标。但难免有一些牵强。