本章是LLaMA系列模型概述,比较简略,涵盖LLaMA-1、LLaMA-2
一、前言
LLaMA是一个系列模型,模型参数量从7B到65B。在大部分的任务上,LLaMA-13B强于GPT-3(175B)。LLaMA-65B的性能,可以和最好的LM相媲美,如Chinchilla-70B 和 PaLM-540B。
二、预训练数据
LLaMa的预训练数据一共有1.4T的tokens,大部分的训练数据都只用了一次,除了Wikipedia 和 Books 使用了大概2个epochs
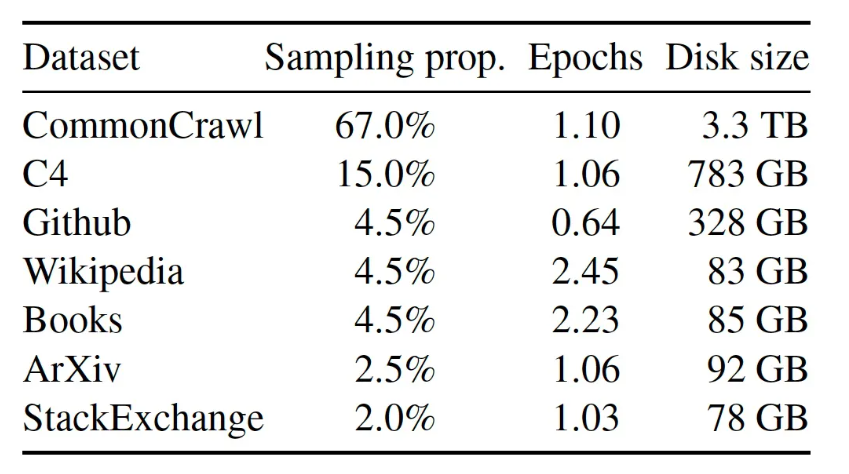
分词使用的是BPE算法
三、网络结构的改进
LLaMa总体还是基于Transformer中Decoder的架构,并做了如下3点改进:
1、Pre-normalization
为了提高训练的稳定性,对每个Decoder的子层的输入进行归一化,而不是输出进行归一化
同时,使用 RMS Norm 归一化函数。RMS Norm 的全称为 Root Mean Square layer normalization。

与 layer Norm 相比,RMS Norm的主要区别在于去掉了减去均值的部分,计算公式为:
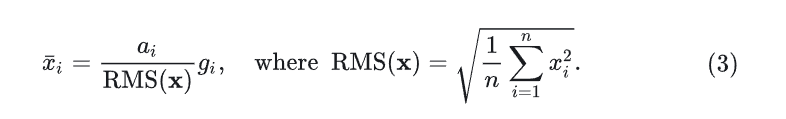
相当于是去掉了均值这项
2、SwiGLU 激活函数
LLaMa 使用 SwiGLU 激活函数替换 ReLU 以提高性能,维度从4d变为2/3 *4d。
SwiGLU 是2019年提出的新的激活函数,它结合了 SWISH 和 GLU 两种者的特点。SwiGLU 主要是为了提升Transformer 中的 FFN(feed-forward network) 层的实现。
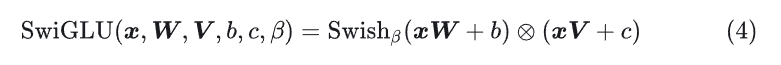
3、Rotary Embeddings
对于attention来说,改变两个词的顺序,并不影响计算的具体数值,改变的知识计算完的矩阵中某两行的值换了位置,因此LLaMa 没有使用之前的绝对位置编码,而是使用了旋转位置编码(RoPE),可以提升模型的外推性。
四、LLaMa2的改进
1、更强大的数据清洗:语料库包括来自公开可用来源的新数据混合,不包括 Meta 的产品或服务的数据。已从某些已知包含大量个人信息的网站中删除数据。
2、总token数量增加了40%:训练使用了2 万亿个token的数据,这在性能和成本之间提供了良好的平衡,通过对最真实的来源进行过采样,以增加知识并减少幻觉。
3、加倍上下文长度:2048->4096,更长的上下文窗口使模型能够处理更多信息,这对于支持聊天应用中的更长历史记录、各种摘要任务和理解更长文档特别有用。
4、70b模型使用了Grouped-query attention (GQA):这是一种方法,允许在多头注意力(MHA)模型中共享键和值投影,从而减少与缓存相关的内存成本。通过使用 GQA,更大的模型可以在优化内存使用的同时保持性能。