本章是GPT系列模型概述,比较简略,涵盖GPT-1、GPT-2、GPT-3
一、前言
GPT 系列是 OpenAI 的一系列预训练模型,全称是 Generative Pre-Trained Transformer
GPT的想法非常简单,因为在NLP中有相当多种类的任务,尽管有大量的未标注数据,但用于指定任务的标注过的数据却很少,这不能很好地评判已训练过的模型性能。 GPT尝试用一种通用,任务无关的模型结构解决所有NLP问题。对于不同的任务,只需要在无监督的预训练后进行有监督的微调就行了,这与CV界的Transfer Learning相同。
ps:GPT系列的模型结构秉承了不断堆叠Transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过不断的提升模型容量和语料规模,模型的能力是可以不断提升的。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
二、GPT-1
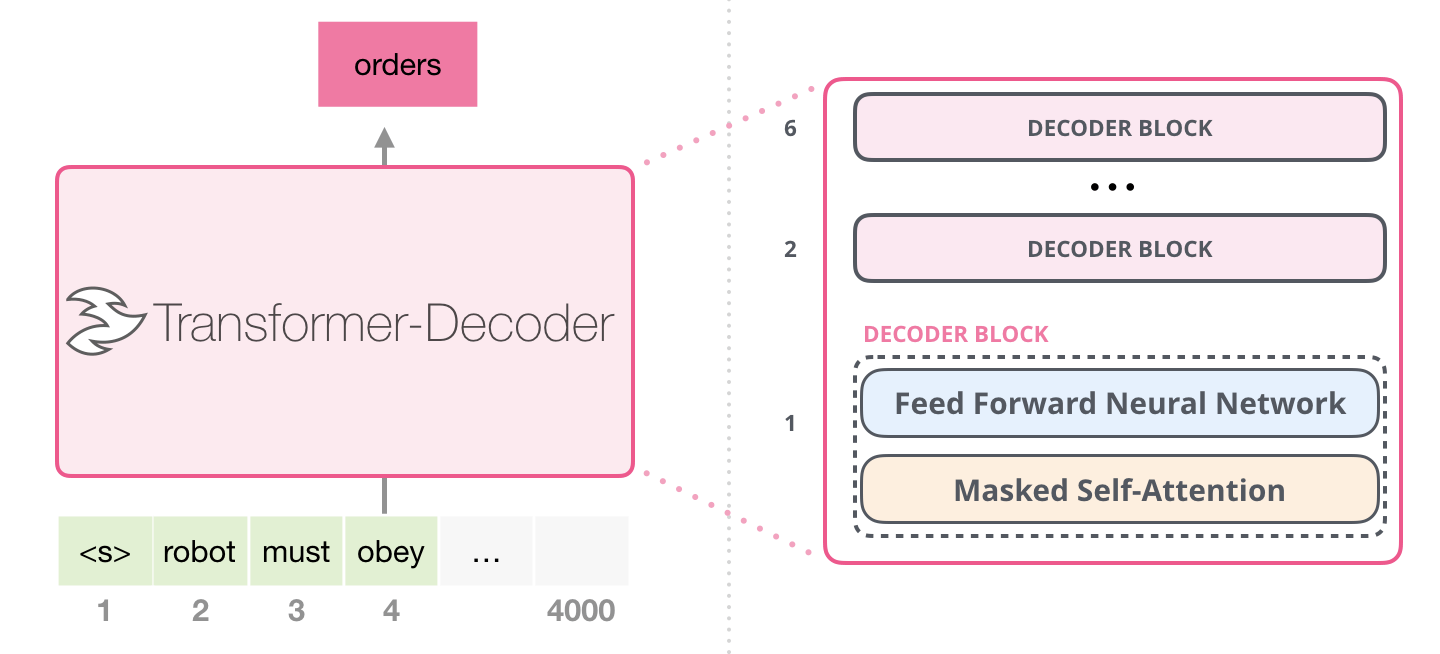
在GPT一代中,采用了12个Decoder堆叠
输入是:Token Embedding + Positional Embedding
Positional Embedding不再是正余弦固定的位置向量,而是采用与词向量相似的随机初始化,并可以在训练中进行更新

第一阶段:无监督预训练
采用标准语言模型,即通过上文预测当前的词
第二阶段:有监督微调
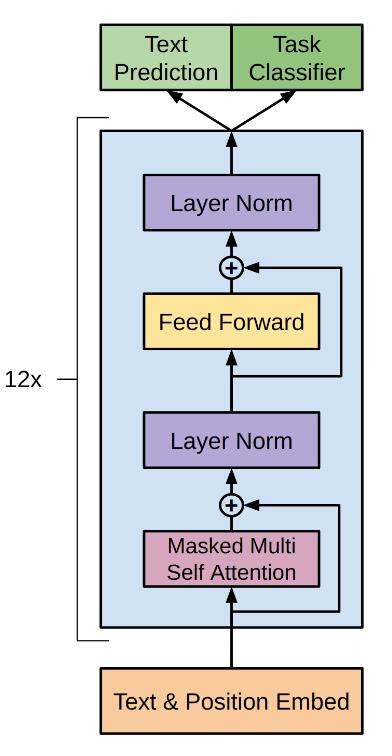
针对不同的下游任务,需要对输入进行转换,从而能够适应 GPT-1 模型结构
原论文在下游任务微调时,除了当前任务的Loss,还加入了预训练阶段语言模型下一个词预测的Loss,实验结果表明效果更好
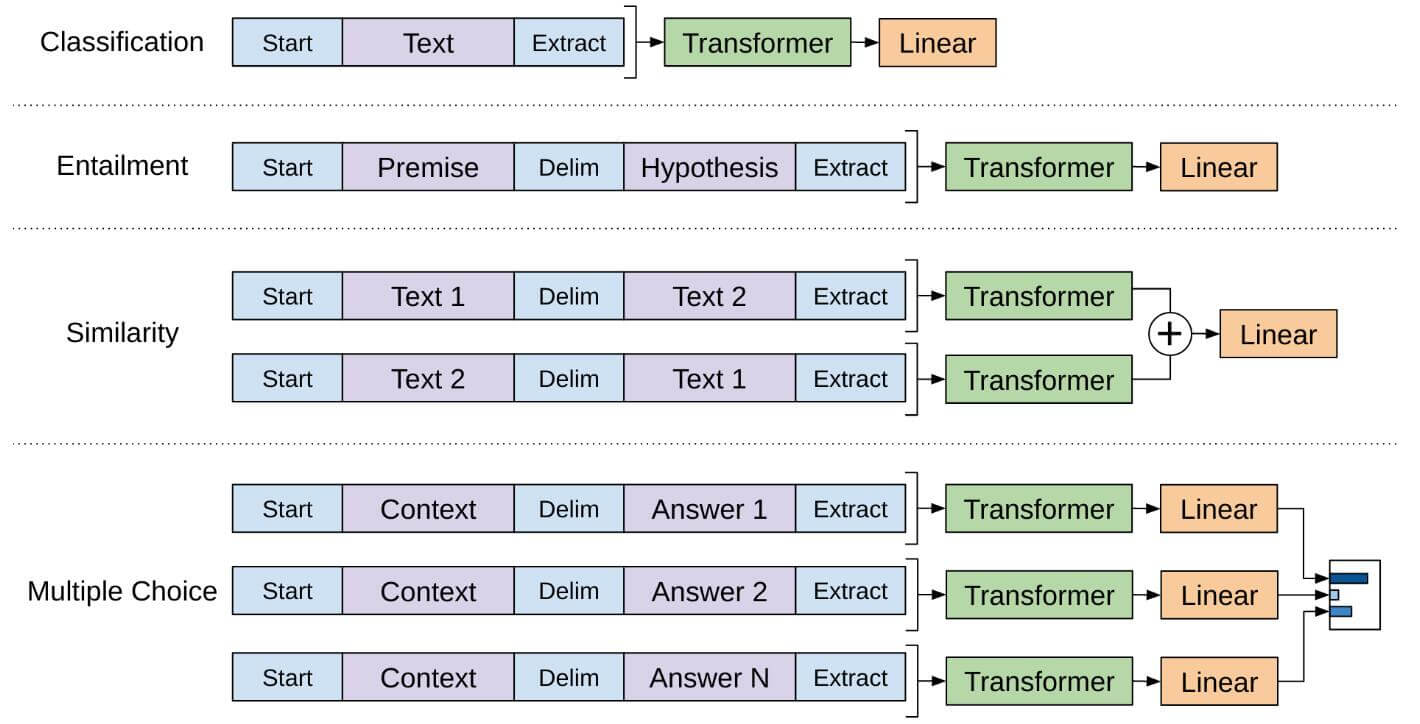
分类任务 只需要在输入序列前后分别加上开始(Start)和结束(Extract)标记
句子关系任务 除了开始和结束标记,在两个句子中间还需要加上分隔符(Delim)
**文本相似性任务 **与句子关系判断任务相似,不同的是需要交换两文本顺序并生成两个文本表示add起来
多项选择任务 文本相似任务的扩展,两个文本扩展为多个文本
都拿最后的Extract去做Linear的label预测
三、GPT-2
BERT用12层编码器效果比GPT-1好,GPT作者不服,他也整的模型更大、数据集更大
但面临的问题可能是,效果仍然比不上BERT,另辟蹊径提出zero-shot能力
- 同样使用了使用字节对编码构建字典,字典的大小为 50,257 ;
- 滑动窗口的大小为 1,024 ;
- batchsize的大小为 512 ;
- Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization;
1代与2代的区别
1、用了更大的数据集, 尤其是网页文本, 40G
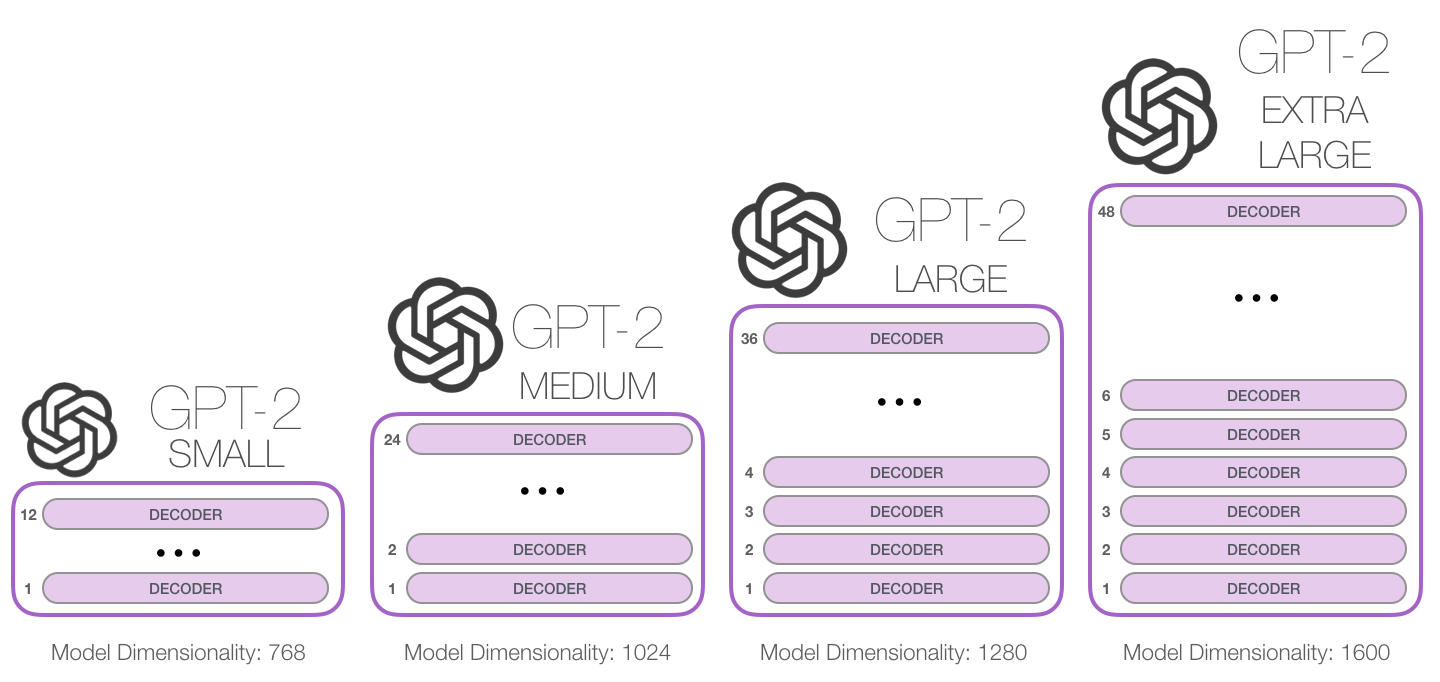
2、增加了海量参数,并推出了几个不同的版本,一个比一个大,除了使用的Decoder个数不同,它们的Embedding维度也是不同的
3、直接去掉了微调层,,直接输入任务和所需的内容就能得到输出
4、Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization
| 参数量 | 层数 | 词向量长度 |
|---|---|---|
| 117M(GPT-1) | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
四、GPT-3
没什么特别大的创新,就是烧钱
模型更大、数据更大,能力更强
开始强调Zero-Shot、Few-Shot能力
效果惊艳