本章介绍ChatGPT及其前身InstructGPT
一、前言
InstructGPT和ChatGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,必须要先读懂InstructGPT。
预训练模型自诞生之始,一个备受诟病的问题就是预训练模型的偏见性。因为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的,对比完全由人工规则控制的专家系统来说,预训练模型就像一个黑盒子。没有人能够保证预训练模型不会生成一些包含种族歧视,性别歧视等危险内容,因为它的几十GB甚至几十TB的训练数据里几乎肯定包含类似的训练样本。这也就是InstructGPT和ChatGPT的提出动机,论文中用3H概括了它们的优化目标:
- 有用的(Helpful);
- 可信的(Honest);
- 无害的(Harmless)
提示(Prompt Learning)学习和指示学习(Instruct Learning)
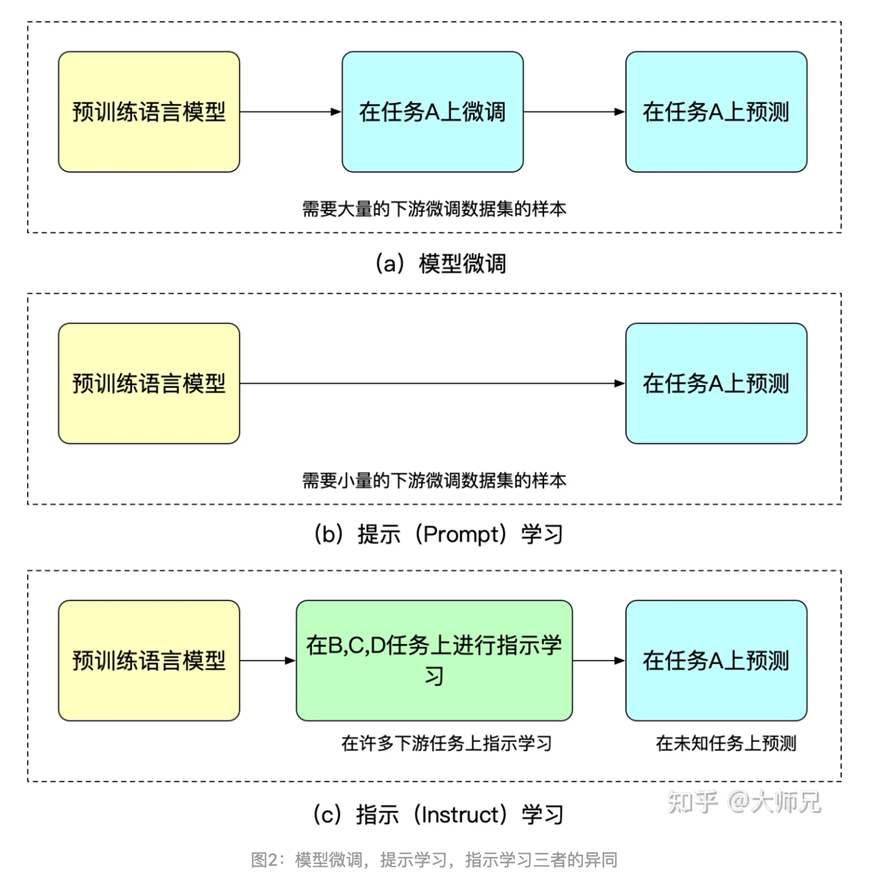
人类反馈强化学习
动机:
巨大的参数量需要海量的数据驱动;
海量的训练数据质量参差不齐;
模型训练过程并不是非常可控的;
我们期望模型的输出内容和人类喜欢的输出内容的对齐,
因为训练得到的模型并不是非常可控的,模型可以看做对训练集分布的一个拟合。那么反馈到生成模型中,训练数据的分布便是影响生成内容的质量最重要的一个因素。有时候我们希望模型并不仅仅只受训练数据的影响,而是人为可控的,从而保证生成数据的有用性,真实性和无害性。论文中多次提到了对齐(Alignment)问题,我们可以理解为模型的输出内容和人类喜欢的输出内容的对齐,人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
我们知道强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模型训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人类反馈的强化学习便应运而生。
二、InstructGPT/ChatGPT原理解读
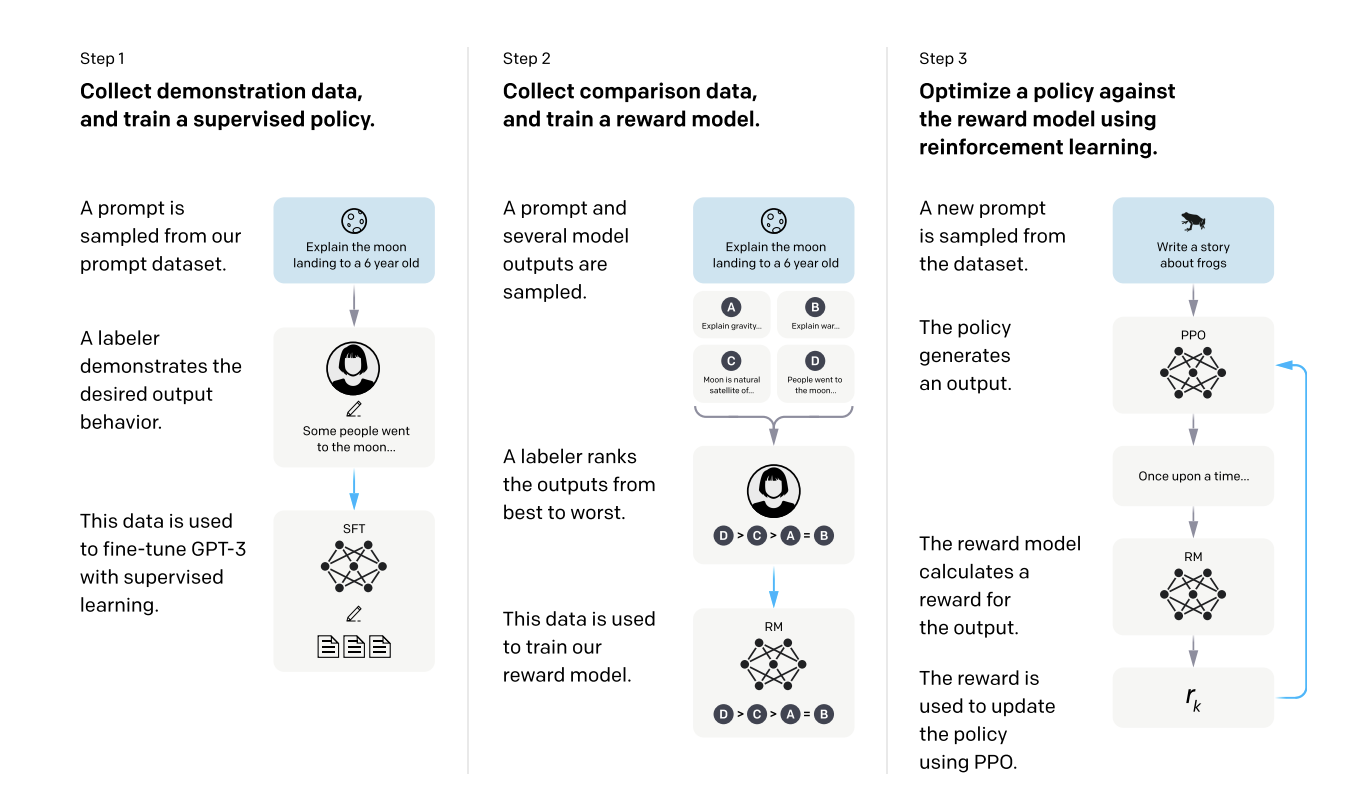
简单来说,InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练
从图中我们可以看出,InstructGPT/ChatGPT的训练可以分成3步,其中第2步和第3步是的奖励模型和强化学习的SFT模型可以反复迭代优化。
1、根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT)
SFT数据集是用来训练第1步有监督的模型,即用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本,提示是数据集里的,答复是来自人工写的,比如SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
- 简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;
- Few-shot任务:labeler给出一个指示,以及该指示的多个查询-响应对;
- 用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示
2、收集人工标注的对比数据,训练奖励模型(Reword Model,RM)
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标,要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序
3、使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型
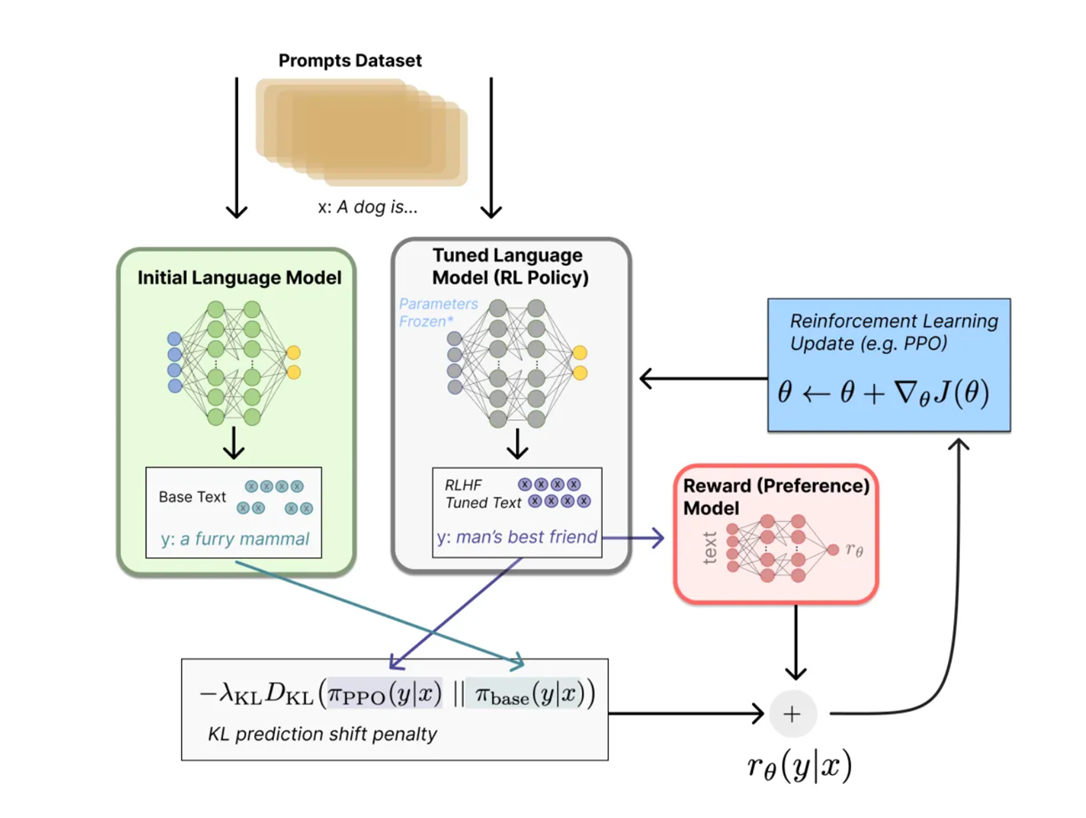
三、训练任务
刚介绍到InstructGPT/ChatGPT有三步训练方式。这三步训练会涉及三个模型:SFT,RM以及PPO,下面详细介绍它们
1、SFT
这一步的训练和GPT-3一致,而且作者发现让模型适当过拟合有助于后面两步的训练
2、RM
想法是可以拿一个小一点的模型,6M的,去充当一个老师的角色,给模型的输出打分
也可以直接用GPT-3去掉最后的softmax层,再接入一个Linear层,output到1的大小,输出相关性分数
最后这些分数会归一化到均值为0
3、利用PPO算法,借助RM模型打的分数,去微调SFT模型
但在微调的时候,为了避免一些错误的reward导致模型学坏,所以微调时策略不能与原来的SFT模型效果差太多